Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。

1、服务器环境及角色分配
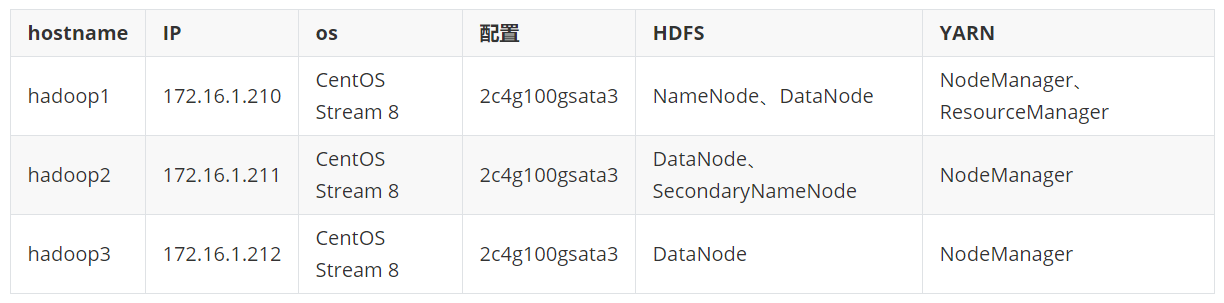
2、服务器免密配置
# 生成ssh 密钥对,一路回车,不输入密码
[root@hadoop1 ~]# ssh-keygen -t rsa
# 把本地的ssh公钥文件安装到远程主机对应的账户
ssh-copy-id -i .ssh/id_rsa.pub hadoop1
ssh-copy-id -i .ssh/id_rsa.pub hadoop2
ssh-copy-id -i .ssh/id_rsa.pub hadoop3
# 3台服务器配置主机名
cat >> /etc/hosts <<EOF
172.16.1.210 hadoop1
172.16.1.211 hadoop2
172.16.1.212 hadoop3
EOF
# 配置Hadoop环境变量
vi /etc/profile
export HADOOP_HOME=/data/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
source /etc/profile
3、安装JDK
# 此软件会提供jps命令,如果不确定什么软件包可提供此命令,可以使用yum provides jps或yum provides */jps
yum install java-1.8.0-openjdk-devel -y
# 验证Java安装是否正常
java -version
4、下载Hadoop二进制软件包并解压
cd /data
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar xf hadoop-3.3.1.tar.gz
5、配置Hadoop并启动,需要修改的配置文件为workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
# 1、修改hadoop-env.sh 添加如下内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-2.el8_5.x86_64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 2、修改核心模块配置文件core-site.xml
<configuration>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9820</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,记得创建目录:mkdir -p /data/hdata/tmp -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hdata/tmp</value>
</property>
<!-- 指定hadoop WEB UI 用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 设置Hadoop的代理用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
# 3、修改hdfs文件系统模块配置:hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量,默认为3个 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定第一个namenode地址和访问端口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 指定第二个namenode地址和访问端口 -->
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop2:9868</value>
</property>
</configuration>
# 4、修改MapReduce模块配置:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 以下优化【注释掉了】参考链接:https://blog.csdn.net/szh1124/article/details/76178699
<property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value>
</property>
-->
</configuration>
# 5、修改yarn模块配置:yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 设置yarn集群主角色的主机 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 历史日志保留的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 以下优化【注释掉了】参考链接:https://blog.csdn.net/szh1124/article/details/76178699
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3096</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>
-->
</configuration>
# 6、修改workers文件,配置任务运行机器
[root@hadoop1 hadoop]# vi workers
hadoop1
hadoop2
hadoop3
6、Hadoop的启停命令
- Hadoop集群(首次启动)需要格式化namenode:
hdfs namenode -format
- Hadoop脚本启停
# 1、启动所有模块命令【不会启动历史服务器,只会启动hdfs和yarn】: start-all.sh
# 2、停止所有模块命令【不会启动历史服务器,只会停止hdfs和yarn】:stop-all.sh
# 3、分模块启停命令:
hdfs模块启停(start-dfs.sh/stop-dfs.sh)
yarn模块启停(start-yarn.sh/stop-yarn.sh)
# 4、Hadoop历史服务器启动,可以查看MapReduce的执行历史
mr-jobhistory-daemon.sh start historyserver
mr-jobhistory-daemon.sh stop historyserver
# 暴力停止Hadoop集群【不推荐,可能会丢失数据】:
jps |grep -iv jps |awk '{print $1}' |xargs kill -9
7、Hadoop集群测试
- hdfs测试
# 上传测试: hadoop fs -put CentOS-8.5.2111-x86_64-boot.iso / # 查看 [root@hadoop1 data]# hadoop fs -ls / Found 3 items -rw-r--r-- 3 root supergroup 827326464 2022-03-18 14:52 /CentOS-8.5.2111-x86_64-boot.iso drwx------ - root supergroup 0 2022-03-19 10:29 /tmp drwxr-xr-x - root supergroup 0 2022-03-07 10:23 /user # 下载测试: hadoop fs -get /CentOS-8.5.2111-x86_64-boot.iso . - MapReduce测试
# 利用Hadoop自带的测试用例测试 pi 圆周率 cd /data/hadoop-3.3.1/share/hadoop/mapreduce # MapReduce测试命令: hadoop jar hadoop-mapreduce-examples-3.3.1.jar pi 10 10
8、Hadoop WEB页面访问
# 1、hdfs WEB界面访问地址:http://172.16.1.210:9870
# 2、yarn WEB界面访问地址:http://172.16.1.210:8088
附录:
Hadoop生态圈介绍:https://blog.csdn.net/yue_2018/article/details/89084266
Hadoop相关服务端口:https://blog.csdn.net/qq_31454379/article/details/105439752







还没有任何评论,你来说两句吧