自从ClickHouse2016年6月15日开源后,ClickHouse中文社区随后成立。中文开源组开始以易观,海康威视,美团,新浪,京东,58,腾讯,酷狗音乐和俄罗斯开源社区等人员组成,随着开源社区的不断活跃,陆续有神州数码,青云,PingCAP,中软国际等公司成员加入以及其他公司成员加入。
Clickhouse官方网站:https://clickhouse.tech/

一、Clickhouse 支持特性剖析
1.真正的面向列的DBMS
在一个真正的面向列的DBMS中,没有任何“垃圾”存储在值中。例如,必须支持定长数值,以避免在数值旁边存储长度“数字”。例如,十亿个UInt8类型的值实际上应该消耗大约1 GB的未压缩磁盘空间,否则这将强烈影响CPU的使用。由于解压缩的速度(CPU使用率)主要取决于未压缩的数据量,所以即使在未压缩的情况下,紧凑地存储数据(没有任何“垃圾”)也是非常重要的。
因为有些系统可以单独存储单独列的值,但由于其他场景的优化,无法有效处理分析查询。例如HBase,BigTable,Cassandra和HyperTable。在这些系统中,每秒钟可以获得大约十万行的吞吐量,但是每秒不会达到数亿行。
另外,ClickHouse是一个DBMS,而不是一个单一的数据库。ClickHouse允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器。
2.数据压缩
一些面向列的DBMS(InfiniDB CE和MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
3.磁盘存储的数据
许多面向列的DBMS(SAP HANA和GooglePowerDrill)只能在内存中工作。但即使在数千台服务器上,内存也太小,无法在Yandex.Metrica中存储所有浏览量和会话。
4.多核并行处理
多核多节点并行化大型查询。
5.在多个服务器上分布式处理
上面列出的列式DBMS几乎都不支持分布式处理。在ClickHouse中,数据可以驻留在不同的分片上。每个分片可以是用于容错的一组副本。查询在所有分片上并行处理。这对用户来说是透明的。
6.SQL支持
如果你熟悉标准的SQL,我们不能真正谈论SQL的支持。NULL不支持。所有的函数都有不同的名字。JOIN支持。子查询在FROM,IN,JOIN子句中被支持;标量子查询支持。关联子查询不支持。
7.向量化引擎
数据不仅按列存储,而且由矢量 – 列的部分进行处理。这使我们能够实现高CPU性能。
8.实时数据更新
ClickHouse支持主键表。为了快速执行对主键范围的查询,数据使用合并树(MergeTree)进行递增排序。由于这个原因,数据可以不断地添加到表中。添加数据时无锁处理。
9.索引
例如,带有主键可以在特定的时间范围内为特定客户端(Metrica计数器)抽取数据,并且延迟时间小于几十毫秒。
10.支持在线查询
这让我们使用该系统作为Web界面的后端。低延迟意味着可以无延迟实时地处理查询,而Yandex.Metrica界面页面正在加载(在线模式)。
11.支持近似计算
1.系统包含用于近似计算各种值,中位数和分位数的集合函数。
2.支持基于部分(样本)数据运行查询并获得近似结果。在这种情况下,从磁盘检索比例较少的数据。
3.支持为有限数量的随机密钥(而不是所有密钥)运行聚合。在数据中密钥分发的特定条件下,这提供了相对准确的结果,同时使用较少的资源。
12.数据复制和对数据完整性的支持。
使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复
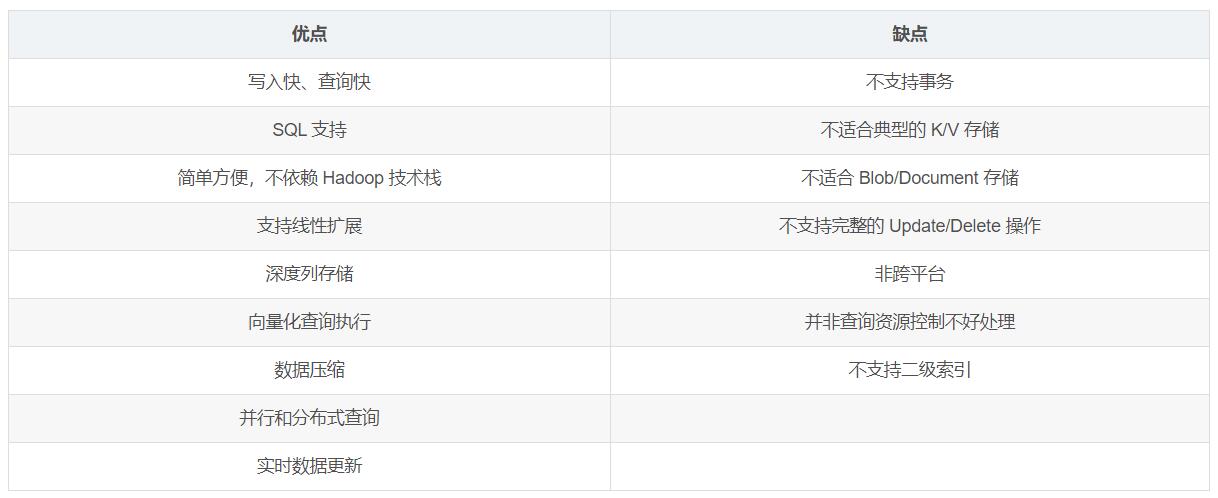
二、ClickHouse的优缺点:
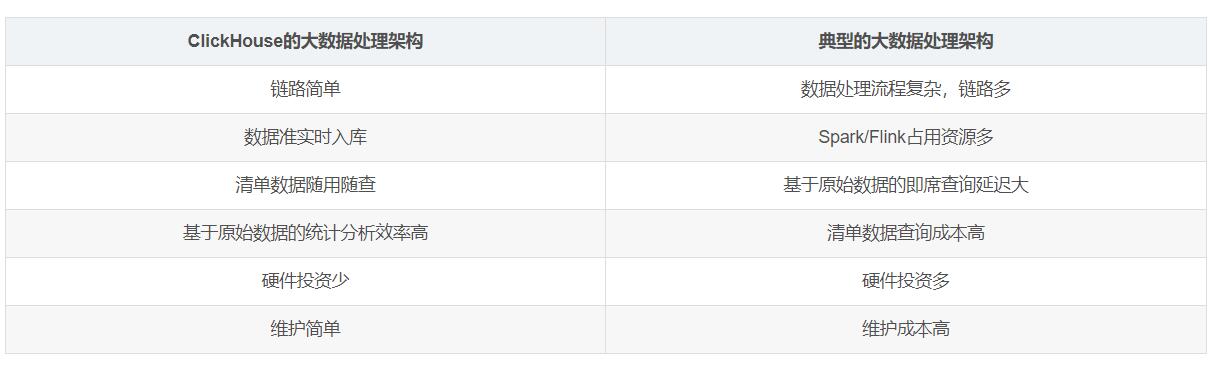
三、ClickHouse的大数据处理架构优点
四、ClickHouse安装,相对比较简单,可参考:https://clickhouse.tech/#quick-start
###配置源
[root@ck01 ~]# yum install yum-utils
[root@ck01 ~]# rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
[root@ck01 ~]# yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo
###安装clickhouse
[root@ck01 ~]# yum install clickhouse-server clickhouse-client
###启动clickhouse
[root@ck01 ~]# systemctl start clickhouse-server
###进入clickhouse数据库终端
[root@ck01 ~]# clickhouse-client
五、clickhouse性能测试:
官方给了很多样例:https://clickhouse.tech/docs/zh/getting-started/example-datasets/
本文以航班数据为样例测试:https://clickhouse.tech/docs/zh/getting-started/example-datasets/ontime/
航班飞行数据有以下两个方式获取:
1、从原始数据导入 (未成功)
2、下载预处理好的分区数据 (成功)
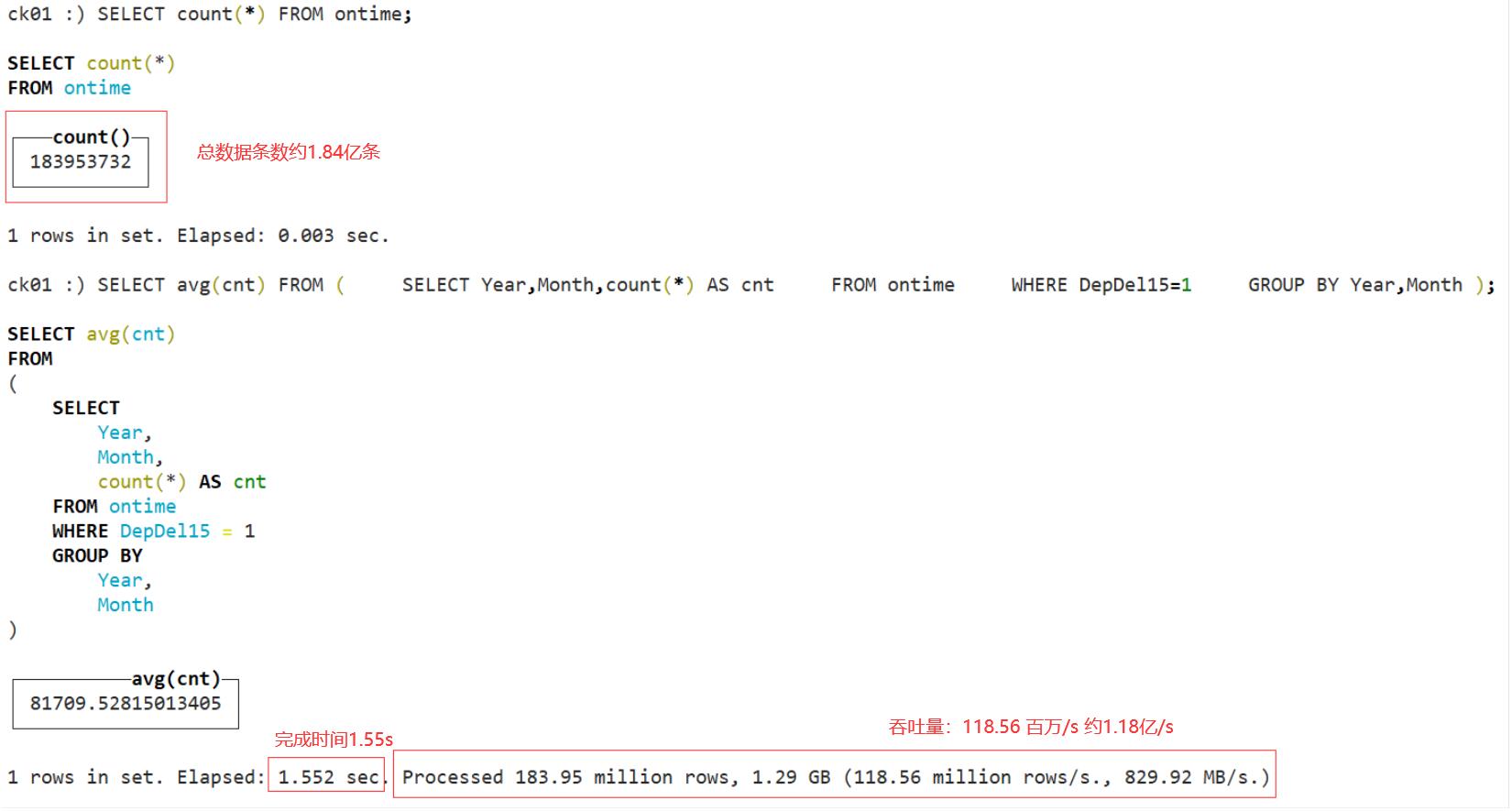
###以第2种方式获取数据:数据容量约16G、数据总条数约1.84亿条、大部分查询在3S内完成。服务器配置:2核4G内存100G SSD固态 8k iops
下载预处理好的分区数据:
[root@ck01 ~]# curl -O https://clickhouse-datasets.s3.yandex.net/ontime/partitions/ontime.tar
[root@ck01 ~]# tar xvf ontime.tar -C /var/lib/clickhouse #ClickHouse data 文件的路径(默认)
[root@ck01 ~]# systemctl restart clickhouse-server
[root@ck01 ~]# clickhouse-client --query "select count(*) from datasets.ontime"
###进入clickhouse数据库终端开始测试:有两种方式clickhouse-client和clickhouse-client -m 区别在于:clickhouse-client -m支持查询语句分行
[root@ck01 ~]# clickhouse-client -m
六、测试结果如下:
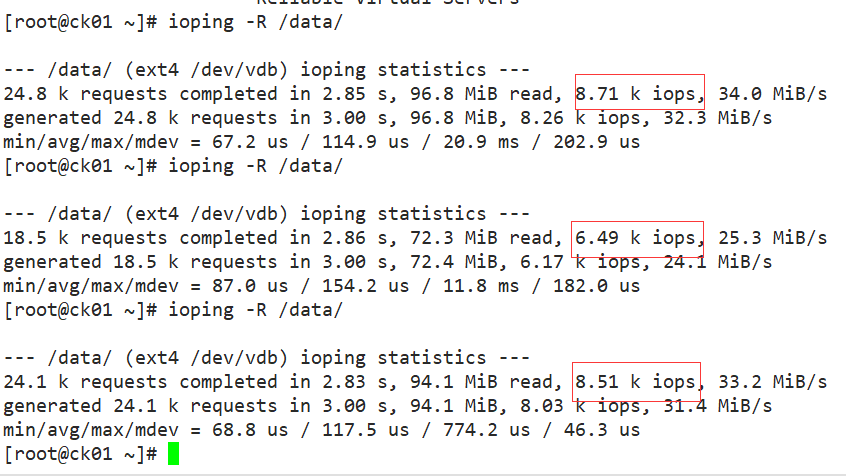
服务器硬盘IO 约8.5K iops







还没有任何评论,你来说两句吧